Добрый вечер! Столкнулся с задачей, связанной с обходом по дереву. Прошу помочь разобраться!!! Ниже, я постараюсь изложить максимально подробно свой вопрос. Он состоит из нескольких под вопросов, потому, прошу вас отнестись к этому с пониманием. Уже давно меня это задача беспокоит) Сразу скажу, что-то решение, которое я представлю здесь - учительское!
ЗАДАНИЕ
findFilesByName.js
Реализуйте и экспортируйте по умолчанию функцию, которая принимает на вход файловое дерево и подстроку, а возвращает список файлов, имена которых содержат эту подстроку.
const tree = mkdir('/', [
mkdir('etc', [
mkdir('apache'),
mkdir('nginx', [
mkfile('nginx.conf', { size: 800 }),
]),
mkdir('consul', [
mkfile('config.json', { size: 1200 }),
mkfile('data', { size: 8200 }),
mkfile('raft', { size: 80 }),
]),
]),
mkfile('hosts', { size: 3500 }),
mkfile('resolve', { size: 1000 }),
]);
findFilesByName(tree, 'co');
// => ['/etc/nginx/nginx.conf', '/etc/consul/config.json']
Обратите внимание на то, что возвращается не просто имя файла, а полный путь до файла, начиная от корня.
Подсказки
Для построения путей используйте функцию path.join.
Проверку вхождения строк можно делать с помощью функции str.includes(substr).
РЕШЕНИЕ УЧИТЕЛЯ
const path = require('path');
const findFilesByName = (root, substr) => {
const { type, children} = root;
const iter = (n, ancestry, acc) => {
const newAncestry = path.join(ancestry, n.name);
if (type == 'file') {
return n.name.includes(substr) ? [...acc, newAncestry] : acc;
}
return n.children.reduce((cAcc, nn) => iter(nn, newAncestry, cAcc), acc);
};
return iter(root, '', []);
};
findFilesByName(tree, 'co');
// => ['/etc/nginx/nginx.conf', '/etc/consul/config.json']
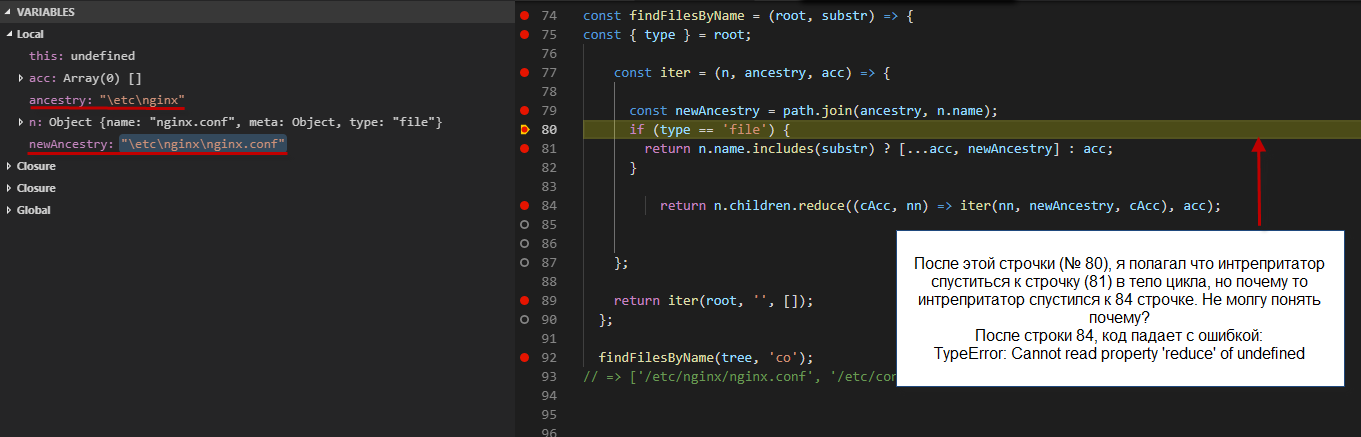
Вопрос № 1
Что происходит в этой строчке, при каждом обращение к reduce? Как меняются его параметры cAcc, nn?
return n.children.reduce((cAcc, nn) => iter(nn, newAncestry, cAcc), acc);
Вопрос № 2
Первый снимок
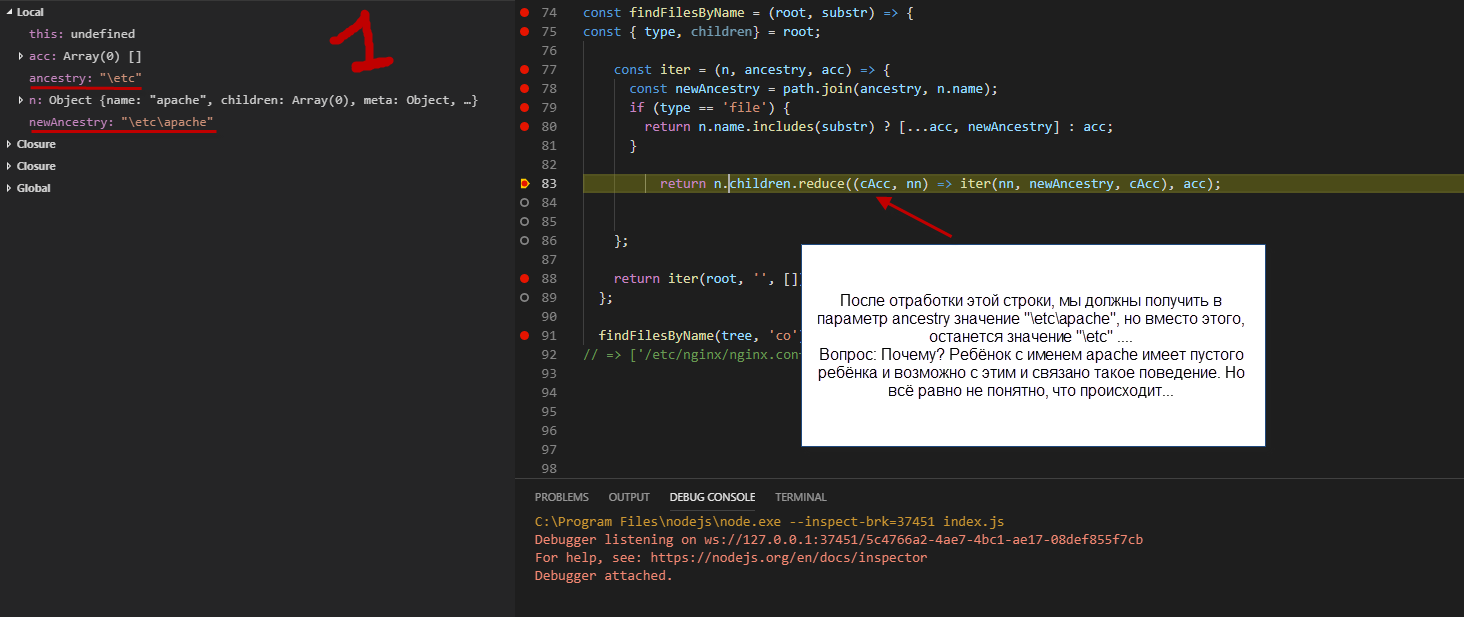
Второй снимок
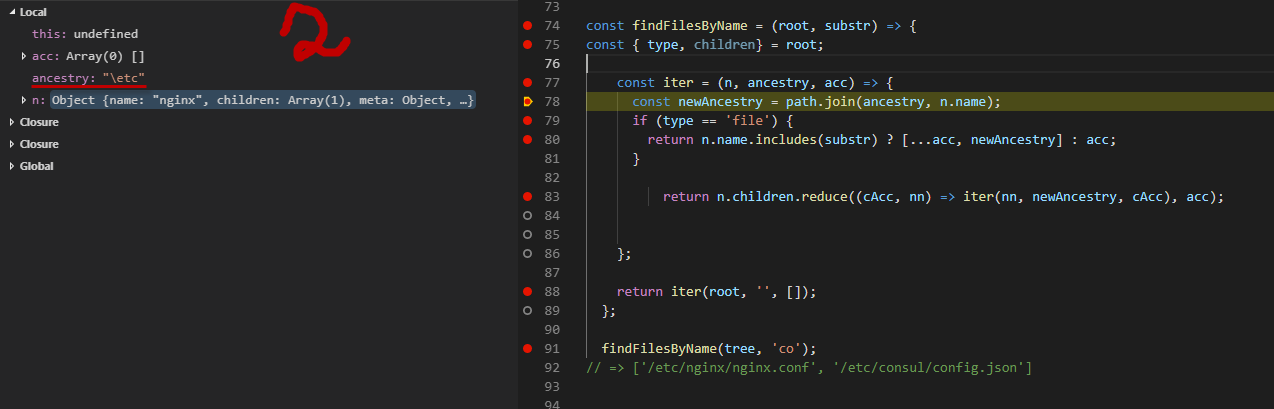
Вопрос № 3
Дерево, по которому работает js код:
let tree = {
"name": "/",
"children": [
{
"name": "etc",
"children": [
{
"name": "apache",
"children": [],
"meta":
{},
"type": "directory"
},
{
"name": "nginx",
"children": [
{
"name": "nginx.conf",
"meta":
{},
"type": "file"
}],
"meta":
{},
"type": "directory"
},
{
"name": "consul",
"children": [
{
"name": "config.json",
"meta":
{},
"type": "file"
},
{
"name": "data",
"children": [],
"meta":
{},
"type": "directory"
}],
"meta":
{},
"type": "directory"
}],
"meta":
{},
"type": "directory"
},
{
"name": "hosts",
"meta":
{},
"type": "file"
},
{
"name": "resolve",
"meta":
{},
"type": "file"
}],
"meta":
{},
"type": "directory"
}